
Pythonでポアソン回帰モデルを作成するメモです。
目次
データの用意
import statsmodels.api as sm
import numpy as np
# 説明変数
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# ポアソン分布に従う目的変数を作成する
np.random.seed(123)
y = np.random.poisson(np.exp(0.4 * x))この例では、平均\(\lambda\)にnp.exp(0.4*x)を渡してポアソン分布に従う変数を作成しています。
ポアソン回帰モデルの作成
上のデータを用いて、ポアソン回帰モデルを作成します。ポアソン回帰モデルは、以下のような対数リンク関数を用いた線形回帰モデルとなっています。
$$\log(\lambda_i)=\beta_0+\beta_1 x_1$$
ここで、(\lambda_i)は平均値、\(x_i\)は説明変数、\(\beta_0\)と\(\beta_1\)は回帰係数です。
ポアソン回帰モデルを作成するためには、以下のようにGLM(Generalized Linear Model)クラスを使用します。
# ポアソン回帰モデルを作成
model = sm.GLM(y, sm.add_constant(x), family=sm.families.Poisson())
# 結果の出力
result.summary()これだけでポアソン回帰モデルが作成できます。最後に、データと回帰曲線をプロットしておきます。
結果を可視化する
# データの散布図をプロットする
plt.scatter(x, y, label='y')
# 回帰直線をプロットする
x_vals = np.linspace(x.min(), x.max(), 100)
y_vals = np.exp(result.params[0] + result.params[1] * x_vals)
plt.plot(x_vals, y_vals, 'r-', label='Regression line')
# プロットの設定
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()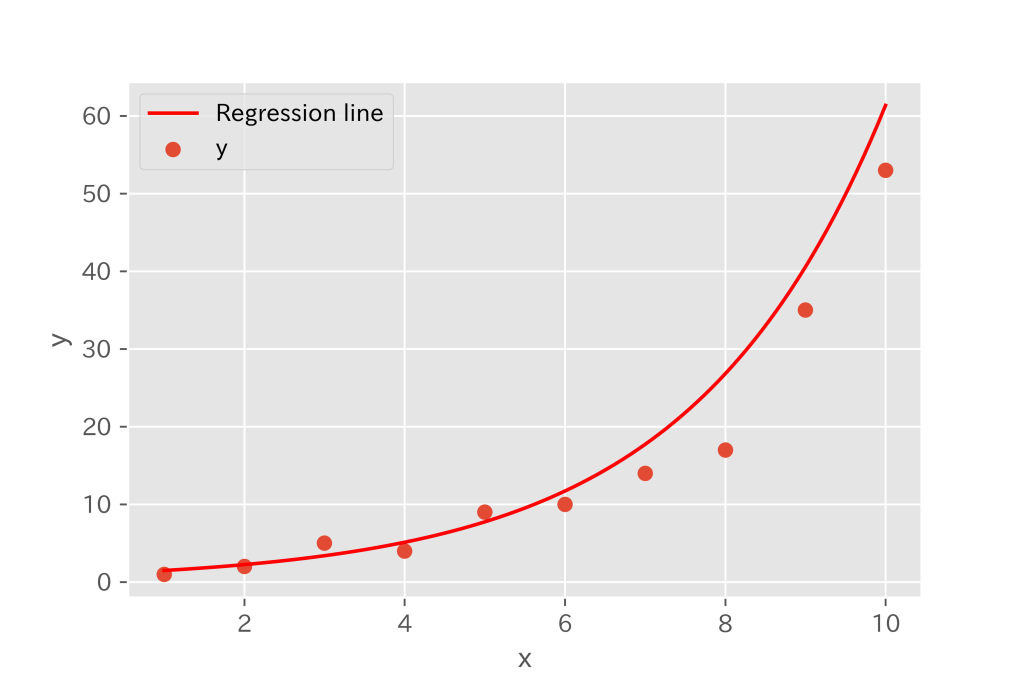
たった数行のコードで、うまくフィッティングできていそうです。
